Java核心
Maven
依赖包
将对应依赖的 jar 包放入classpath,进行依赖包管理
项目目录结构
src 存放Java源码,resources 存放配置文件,bin 存放编译生成的.class文件
配置环境
例如JDK的版本,编译打包的流程,当前代码的版本号
Maven即对以上标准化的Java项目管理和构建工具,它的主要功能有:
- 提供了一套标准化的项目结构
- 提供了一套标准化的构建流程(编译,测试,打包,发布……)
- 提供了一套依赖管理机制

以上就是一个Maven项目的标准目录结构:
项目的根目录项目名,它有一个项目描述文件 pom.xml
存放Java源码的目录是 src/main/java
存放资源文件的目录是 src/main/resources
存放测试源码的目录是 src/test/java
存放测试资源的目录是 src/test/resources
最后,所有编译、打包生成的文件都放在 target 目录里
安装Maven
Maven官网下载最新的Maven,然后在本地解压,设置几个系统环境变量:
MAVEN_HOME=D:\apache-maven-3.9.7
PATH=$PATH:$MAVEN_HOME/bin
或path新增:
%MAVEN_HOME%\bin\
命令行窗口输入 mvn -version,查看 Maven 的版本信息
IDEA设置
”文件“—“设置”—“构建工具”—“Maven”
设置“主路径”为maven目录:D:\apache-maven-3.9.7
设置“用户设置文件”:D:\apache-maven-3.9.7\conf\setting.xml
设置“本地仓库”:D:\apache-maven-3.9.7\maven_repository(手动新建)
pom.xml
作为项目描述文件,内容包括
<project ...>
<modelVersion>4.0.0</modelVersion>
<groupId>com.itranswarp.learnjava</groupId>
<artifactId>hello</artifactId>
<version>1.0</version>
<packaging>jar</packaging>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.2</version>
</dependency>
</dependencies>
<build>
...
</build>
</project>
groupId 类似于Java的包名,通常是公司或组织名称
artifactId 类似于Java的类名,通常是项目名称
version 来配合 groupId,artifactId 对一个Maven工程就是由作为唯一标识
<dependency> 声明一个依赖后,Maven就会自动下载这个依赖包并把它放到classpath中
依赖管理
繁琐的过程是通过搜索引擎搜索到依赖包项目官网,然后手动下载zip包,解压,放入classpath
Maven会自动解析并判断依赖关系,包括以下几种依赖关系:
| scope | 说明 | 示例 |
|---|---|---|
| compile | 编译时需要用到该jar包(默认) | commons-logging |
| test | 编译Test时需要用到该jar包 | junit |
| runtime | 编译时不需要,但运行时需要用到 | mysql |
| provided | 编译时需要用到,但运行时由JDK或某个服务器提供 | servlet-api |
默认的compile是最常用的,Maven会把这种类型的依赖直接放入classpath
test依赖表示仅在测试时使用,正常运行时并不需要。最常用的test依赖就是JUnit
runtime依赖表示编译时不需要,但运行时需要。最典型的runtime依赖是JDBC驱动,例如MySQL驱动
provided依赖表示编译时需要,但运行时不需要。最典型的provided依赖是Servlet API,编译的时候需要,但是运行时,Servlet服务器内置了相关的jar,所以运行期不需要
Maven库
Maven维护了一个中央仓库(repo1.maven.org),所有第三方库将自身的jar以及相关信息上传至中央仓库,Maven就可以从中央仓库把所需依赖下载到本地
中国区用户可以使用阿里云提供的Maven镜像仓库。使用Maven镜像仓库需要一个配置,在用户主目录下进入 .m2 目录,创建一个settings.xml配置文件,内容如下:
<settings>
<mirrors>
<mirror>
<id>aliyun</id>
<name>aliyun</name>
<mirrorOf>central</mirrorOf>
<!-- 国内推荐阿里云的Maven镜像 -->
<url>https://maven.aliyun.com/repository/central</url>
</mirror>
</mirrors>
</settings>
快速引入库
引用一个第三方组件,获得它的 groupId、artifactId 和 version
可通过 search.maven.org 搜索关键字,找到对应的组件后复制dependency
或 mvnrepository 查看包的下载量最高版本
编译为jar包
在命令中,进入到pom.xml所在目录,输入命令 mvn clean package
构建流程
除了标准化的项目结构,Maven还有一套标准化构建流程,自动化实现编译,打包,发布等
生命周期(Lifecycle)
Maven的生命周期由一系列阶段(phase)构成,如 default 生命周期包含 compile test package 等
运行 mvn package,Maven就会执行 default 生命周期,从开始一直运行到 package 这个phase为止
goal:执行一个phase又会触发一个或多个goal,命名总是abc:xyz这种形式,如 mvn tomcat:run
-
lifecycle相当于Java的package,它包含一个或多个phase
-
phase相当于Java的class,它包含一个或多个goal
-
goal相当于class的method,它其实才是真正干活的
常见构建命令
mvn clean:清理所有生成的class和jar;
mvn clean compile:先清理,再执行到compile;
mvn clean test:先清理,再执行到test,因为执行test前必须执行compile,所以这里不必指定compile;
mvn clean package:先清理,再执行到package。
模块管理
Maven支持模块化管理,可以把一个大项目拆成几个模块:
- 可以通过继承在parent的
pom.xml统一定义重复配置; - 可以通过
<modules>编译多个模块。
发布Artifact
配置
pom.xml 添加 <distributionManagement>,它指示了发布的软件包的位置,其中:
<url>是项目根目录下的 maven-repo 目录
<build>中定义的两个插件maven-source-plugin和maven-javadoc-plugin分别用来创建源码和javadoc,如果不想发布源码,可以把对应的插件去掉
打包
项目根目录下运行Maven命令 mvn clean package deploy, 部署文件将存放到 maven-repo 目录
可以利用 github Pages 提供静态资源服务,最终jar包地址类似:
https://michaelliao.github.io/how-to-become-rich/maven-repo/com/itranswarp/rich/how-to-become-rich/1.0.0/how-to-become-rich-1.0.0.jar`
引用
<dependency>
<groupId>com.itranswarp.rich</groupId>
<artifactId>how-to-become-rich</artifactId>
<version>1.0.0</version>
</dependency>
此外,补充 <repository> 声明 <id>、<name> 和 <url>
Nexus 作为Maven仓库管理软件,很多大公司内部都使用Nexus作为自己的私有Maven仓库;
而central.sonatype.org相当于面向开源的一个Nexus公共服务,实现将jar包发布到Maven中央仓库
网络编程
TCP编程
Socket是一个抽象概念,应用程序通过Socket来建立远程连接,而Socket内部通过TCP/IP协议把数据传输到网络
Socket、TCP和部分IP的功能都是由操作系统提供的,不同的编程语言只是提供了对操作系统调用的简单的封装。
为什么需要Socket进行网络通信?因为仅仅通过IP地址进行通信是不够的,同一台计算机同一时间会运行多个网络应用程序。当操作系统接收到一个数据包的时候,如果只有IP地址,它没法判断应该发给哪个应用程序,所以,操作系统抽象出Socket接口,每个应用程序需要各自对应到不同的Socket,数据包才能根据Socket正确地发到对应的应用程序。
一个Socket就是由IP地址和端口号(范围是0~65535)组成 101.202.99.2:1201
Socket进行网络编程时,本质上就是两个进程之间的网络通信。其中一个进程必须充当服务器端,它会主动监听某个指定的端口,另一个进程必须充当客户端,它必须主动连接服务器的IP地址和指定端口,如果连接成功,服务器端和客户端就成功地建立了一个TCP连接,双方后续就可以随时发送和接收数据。
因此,当Socket连接成功地在服务器端和客户端之间建立后:
- 对服务器端来说,它的Socket是指定的IP地址和指定的端口号;
- 对客户端来说,它的Socket是它所在计算机的IP地址和一个由操作系统分配的随机端口号。
服务器端
Java标准库提供了ServerSocket来实现对指定IP和指定端口的监听
import java.io.*;
import java.net.*;
import java.nio.charset.*;
public class Server {
public static void main(String[] args) throws IOException {
ServerSocket ss = new ServerSocket(6666); // 监听指定端口
System.out.println("server is running...");
for (;;) {
Socket sock = ss.accept();
System.out.println("connected from " + sock.getRemoteSocketAddress());
Thread t = new Handler(sock);
t.start();
}
}
}
class Handler extends Thread {
Socket sock;
public Handler(Socket sock) {
this.sock = sock;
}
@Override
public void run() { // 建立连接后,线程start时
try (InputStream input = this.sock.getInputStream()) {
try (OutputStream output = this.sock.getOutputStream()) {
handle(input, output);
}
} catch (Exception e) {
try {
this.sock.close();
} catch (IOException ioe) {
}
System.out.println("client disconnected.");
}
}
private void handle(InputStream input, OutputStream output) throws IOException {
var writer = new BufferedWriter(new OutputStreamWriter(output, StandardCharsets.UTF_8));
var reader = new BufferedReader(new InputStreamReader(input, StandardCharsets.UTF_8));
writer.write("hello\n");
writer.flush();
for (;;) {
String s = reader.readLine();
if (s.equals("bye")) {
writer.write("bye\n");
writer.flush();
break;
}
writer.write("ok: " + s + "\n");
writer.flush();
}
}
}
-
指定端口
6666监听。这里我们没有指定IP地址,表示在计算机的所有网络接口上进行监听:ServerSocket ss = new ServerSocket(6666); -
ServerSocket监听成功,我们就使用一个无限循环来处理客户端的连接:for (;;) { Socket sock = ss.accept(); // 未接收到新连接将阻塞... Thread t = new Handler(sock); t.start(); } -
ss.accept()表示每当有新的客户端连接进来后,就返回一个Socket实例,这个Socket实例就是用来和刚连接的客户端进行通信的。由于客户端很多,要实现并发处理,我们就必须为每个新的Socket创建一个新线程来处理,这样,主线程的作用就是接收新的连接,每当收到新连接后,就创建一个新线程进行处理。
客户端
public class Client {
public static void main(String[] args) throws IOException {
Socket sock = new Socket("localhost", 6666); // 连接指定服务器和端口
try (InputStream input = sock.getInputStream()) {
try (OutputStream output = sock.getOutputStream()) {
handle(input, output);
}
}
sock.close();
System.out.println("disconnected.");
}
private static void handle(InputStream input, OutputStream output) throws IOException {
var writer = new BufferedWriter(new OutputStreamWriter(output, StandardCharsets.UTF_8));
var reader = new BufferedReader(new InputStreamReader(input, StandardCharsets.UTF_8));
Scanner scanner = new Scanner(System.in);
System.out.println("[server] " + reader.readLine());
for (;;) {
System.out.print(">>> "); // 打印提示
String s = scanner.nextLine(); // 读取一行输入
writer.write(s);
writer.newLine();
writer.flush();
String resp = reader.readLine();
System.out.println("<<< " + resp);
if (resp.equals("bye")) {
break;
}
}
}
}
HTTP编程
Java 11开始,引入了新的HttpClient,它使用链式调用的API,能大大简化HTTP的处理。
创建一个全局HttpClient实例,因为 HttpClient 内部使用线程池优化多个HTTP连接,
static HttpClient httpClient = HttpClient.newBuilder().build();
GET 请求获取文本内容:
import java.net.URI;
import java.net.http.*;
import java.net.http.HttpClient.Version;
import java.time.Duration;
import java.util.*;
public class Main {
// 全局HttpClient:
static HttpClient httpClient = HttpClient.newBuilder().build();
public static void main(String[] args) throws Exception {
String url = "https://www.sina.com.cn/";
// HttpRequest.newBuilder构造请求
HttpRequest request = HttpRequest.newBuilder(new URI(url))
// 设置Header:
.header("User-Agent", "Java HttpClient").header("Accept", "*/*")
// 设置超时:
.timeout(Duration.ofSeconds(5))
// 设置版本:
.version(Version.HTTP_2).build();
// send请求,接收响应
HttpResponse<String> response = httpClient.send(request, HttpResponse.BodyHandlers.ofString());
// HTTP允许重复的Header,因此一个Header可对应多个Value:
Map<String, List<String>> headers = response.headers().map();
for (String header : headers.keySet()) {
System.out.println(header + ": " + headers.get(header).get(0));
}
System.out.println(response.body().substring(0, 1024) + "...");
}
}
获取图片这样的二进制内容,只需要把HttpResponse.BodyHandlers.ofString()换成HttpResponse.BodyHandlers.ofByteArray(),就可以获得一个HttpResponse<byte[]>对象。如果响应的内容很大,不希望一次性全部加载到内存,可以使用HttpResponse.BodyHandlers.ofInputStream()获取一个InputStream流。
POST请求,设置好发送的Body数据并正确设置 Content-Type
String url = "http://www.example.com/login";
String body = "username=bob&password=123456";
HttpRequest request = HttpRequest.newBuilder(new URI(url))
// 设置Header:
.header("Accept", "*/*")
.header("Content-Type", "application/x-www-form-urlencoded") // 编码类型
// 设置超时:
.timeout(Duration.ofSeconds(5))
// 设置版本:
.version(Version.HTTP_2)
// 使用POST并设置Body:
.POST(BodyPublishers.ofString(body, StandardCharsets.UTF_8)).build();
HttpResponse<String> response = httpClient.send(request, HttpResponse.BodyHandlers.ofString());
String s = response.body();
函数式编程
Stream
一个全新的流式API:Stream API。它位于java.util.stream包中
| java.io | java.util.stream | |
|---|---|---|
| 存储 | 顺序读写的byte或char |
顺序输出的任意Java对象实例 |
| 用途 | 序列化至文件或网络 | 内存计算/业务逻辑 |
| java.util.List | java.util.stream | |
|---|---|---|
| 元素 | 已分配并存储在内存 | 可能未分配,实时计算 |
| 用途 | 操作一组已存在的Java对象 | 惰性计算 |
Stream<BigInteger> naturals = createNaturalStream(); // 全体自然数
Stream<BigInteger> streamNxN = naturals.map(n -> n.multiply(n)); // 全体自然数的平方
特点:
它可以“存储”有限个或无限个元素。这里的存储可能已经全部存储在内存中,也有可能是根据需要实时计算出来的
一个Stream可以轻易地转换为另一个Stream,链式操作;
惰性计算:Stream相互转换时,并没有任何计算发生
createNaturalStream()
.map(BigInteger::multiply)
.limit(100)
.forEach(System.out::println);
创建一个Stream,然后做若干次转换,最后调用一个求值方法获取真正计算的结果:
int result = createNaturalStream() // 创建Stream
.filter(n -> n % 2 == 0) // 任意个转换
.map(n -> n * n) // 任意个转换
.limit(100) // 任意个转换
.sum(); // 最终计算结果
创建Stream
Stream.of() 传入可变参数即创建了一个能输出确定元素的 Stream,常用于测试
public static void main(String[] args) {
Stream<String> stream = Stream.of("A", "B", "C", "D");
// forEach()方法相当于内部循环调用,
// 可传入符合Consumer接口的void accept(T t)的方法引用:
stream.forEach(System.out::println);
}
基于数组或Collection
public static void main(String[] args) {
Stream<String> stream1 = Arrays.stream(new String[] { "A", "B", "C" });
Stream<String> stream2 = List.of("X", "Y", "Z").stream();
stream1.forEach(System.out::println);
stream2.forEach(System.out::println);
}
其他方法
创建Stream的第三种方法是通过一些API提供的接口,直接返回Stream。
Files类的lines()方法可以把一个文件变成一个Stream,每个元素代表文件的一行内容(按行遍历文本文件)
正则表达式的Pattern对象有一个splitAsStream()方法,可以直接把一个长字符串分割成Stream序列而不是数组
基本类型
因为Java的范型不支持基本类型,所以我们无法用Stream<int>这样的类型,会发生编译错误。
为了保存int,只能使用Stream<Integer>,但这样会产生频繁的装箱、拆箱操作。为了提高效率,Java标准库提供了IntStream、LongStream和DoubleStream这三种使用基本类型的Stream,它们的使用方法和范型Stream没有大的区别,设计这三个Stream的目的是提高运行效率:
// 将int[]数组变为IntStream:
IntStream is = Arrays.stream(new int[] { 1, 2, 3 });
// 将Stream<String>转换为LongStream:
LongStream ls = List.of("1", "2", "3").stream().mapToLong(Long::parseLong);
map、filter
Stream最常用的转换方法,按规则把一个Stream转换为另一个Stream
public static void main(String[] args) {
List.of(" Apple ", " pear ", " ORANGE", " BaNaNa ")
.stream()
.map(String::trim) // 去空格
.map(String::toLowerCase) // 变小写
.forEach(System.out::println); // 打印
}
public static void main(String[] args) {
IntStream.of(1, 2, 3, 4, 5, 6, 7, 8, 9)
.filter(n -> n % 2 != 0)
.forEach(System.out::println);
}
reduce
Stream的一个聚合方法,它可以把一个Stream的所有元素按照聚合函数聚合成一个结果
int sum = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9).reduce(0, (acc, n) -> acc + n);
System.out.println(sum); // 45
// 按行读取配置文件:
List<String> props = List.of("profile=native", "debug=true", "logging=warn", "interval=500");
Map<String, String> map = props.stream()
// 把k=v转换为Map[k]=v:
.map(kv -> {
String[] ss = kv.split("\\=", 2);
return Map.of(ss[0], ss[1]);
})
// 把所有Map聚合到一个Map:
.reduce(new HashMap<String, String>(), (m, kv) -> {
m.putAll(kv);
return m;
});
// 打印结果:
map.forEach((k, v) -> {
System.out.println(k + " = " + v);
});
输出集合
输出为List
List<String> list = stream
.filter(s -> s != null && !s.isBlank())
.collect(Collectors.toList());
输出为数组
String[] array = list.stream().toArray(String[]::new);
输出为Map
Stream<String> stream = Stream.of("APPL:Apple", "MSFT:Microsoft");
Map<String, String> map = stream
.collect(Collectors.toMap(
// 把元素s映射为key:
s -> s.substring(0, s.indexOf(':')),
// 把元素s映射为value:
s -> s.substring(s.indexOf(':') + 1)));
System.out.println(map);
分组输出
List<String> list = List.of("Apple", "Banana", "Blackberry", "Coconut", "Avocado", "Cherry", "Apricots");
Map<String, List<String>> groups = list.stream()
.collect(Collectors.groupingBy(s -> s.substring(0, 1), Collectors.toList()));
System.out.println(groups);
分组输出使用Collectors.groupingBy(),它需要提供两个函数:
一个是分组的key,这里使用s -> s.substring(0, 1),表示只要首字母相同的String分到一组;
第二个是分组的value,这里直接使用Collectors.toList(),表示输出为List;
.sort
此方法要求Stream的每个元素必须存在Comparable接口。如果要自定义排序,传入指定的Comparator即可:
List<String> list = List.of("Orange", "apple", "Banana")
.stream()
.sorted(String::compareToIgnoreCase)
.collect(Collectors.toList());
distinct
List.of("A", "B", "A", "C", "B", "D")
.stream()
.distinct()
.collect(Collectors.toList()); // [A, B, C, D]
skip
List.of("A", "B", "C", "D", "E", "F")
.stream()
.skip(2) // 跳过A, B
.limit(3) // 截取C, D, E
.collect(Collectors.toList()); // [C, D, E]
concat
Stream<String> s1 = List.of("A", "B", "C").stream();
Stream<String> s2 = List.of("D", "E").stream();
// 合并:
Stream<String> s = Stream.concat(s1, s2);
System.out.println(s.collect(Collectors.toList())); // [A, B, C, D, E]
flatMap
Stream<List<Integer>> s = Stream.of(
Arrays.asList(1, 2, 3),
Arrays.asList(4, 5, 6),
Arrays.asList(7, 8, 9)
));
Stream<Integer> i = s.flatMap(list -> list.stream());
parallel
Stream<String> s = ...
String[] result = s.parallel() // 变成一个可以并行处理的Stream
.sorted() // 可以进行并行排序
.toArray(String[]::new);
其它聚合方法
count():用于返回元素个数;max(Comparator<? super T> cp):找出最大元素;min(Comparator<? super T> cp):找出最小元素。
针对IntStream、LongStream和DoubleStream,还额外提供了以下聚合方法:
sum():对所有元素求和;average():对所有元素求平均数。
还有一些方法,用来测试Stream的元素是否满足以下条件:
boolean allMatch(Predicate<? super T>):测试是否所有元素均满足测试条件;boolean anyMatch(Predicate<? super T>):测试是否至少有一个元素满足测试条件。
Web开发
前面介绍的所有基于标准JDK的开发都是JavaSE,Java Web内容开始正式进入到JavaEE的领域,即Java企业平台。
JavaEE是在JavaSE的基础上,开发的一系列基于服务器的组件、API标准和通用架构
最核心的组件就是基于Servlet标准的Web服务器,开发者编写的应用程序是基于Servlet API并运行在Web服务器内部的:
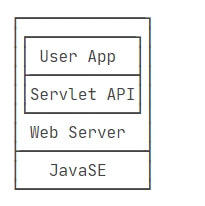
目前流行的基于Spring的轻量级JavaEE开发架构,使用最广泛的是Servlet和JMS,以及一系列开源组件
编写HTTP Server
HTTP Server本质上是一个TCP服务器,我们先用 TCP编程 的多线程实现的服务器端框架
Servlet入门
// WebServlet注解表示这是一个Servlet,并映射到地址/:
@WebServlet(urlPatterns = "/")
public class HelloServlet extends HttpServlet {
protected void doGet(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
// 设置响应类型:
resp.setContentType("text/html");
// 获取输出流:
PrintWriter pw = resp.getWriter();
// 写入响应:
pw.write("<h1>Hello, world!</h1>");
// 最后不要忘记flush强制输出:
pw.flush();
}
}
普通的Java程序是通过启动JVM,然后执行 main() 方法开始运行
Web应用程序中,无法直接运行 war 文件,必须先启动Web服务器,再由Web服务器加载编写的HelloServlet,这样就可以让 HelloServlet 处理浏览器发送的请求
运行
运行Maven命令 mvn clean package,target 目录下得到war文件,即编译打包后的Web应用程序;
下载 tomcat服务器,把war包复制到Tomcat的 webapps 目录下,切换到bin目录,执行startup.sh 或 startup.bat 启动Tomcat服务器